El reto
Un archivo histórico con miles de páginas del Registro Oficial y documentos del s. XIX–XX plantea un problema doble: por un lado, el OCR clásico falla con papel envejecido, tipografías irregulares y columnas tipográficas; por otro, la búsqueda por palabra exacta es inservible cuando la ortografía varía entre décadas, abundan las abreviaturas legales y los conceptos se expresan con vocabulario distinto en cada época.
El objetivo no era sólo “convertir imágenes en texto”. Era hacer que un investigador pueda preguntarle al archivo por concepto — y que el archivo responda con citas a la fuente original.
La solución
BiblioOCR es una plataforma que combina OCR multi-motor, embeddings vectoriales y visualización 3D del corpus para digitalizar, indexar semánticamente y explorar archivos históricos enteros desde un mismo flujo.
OCR multi-motor con flujo de revisión
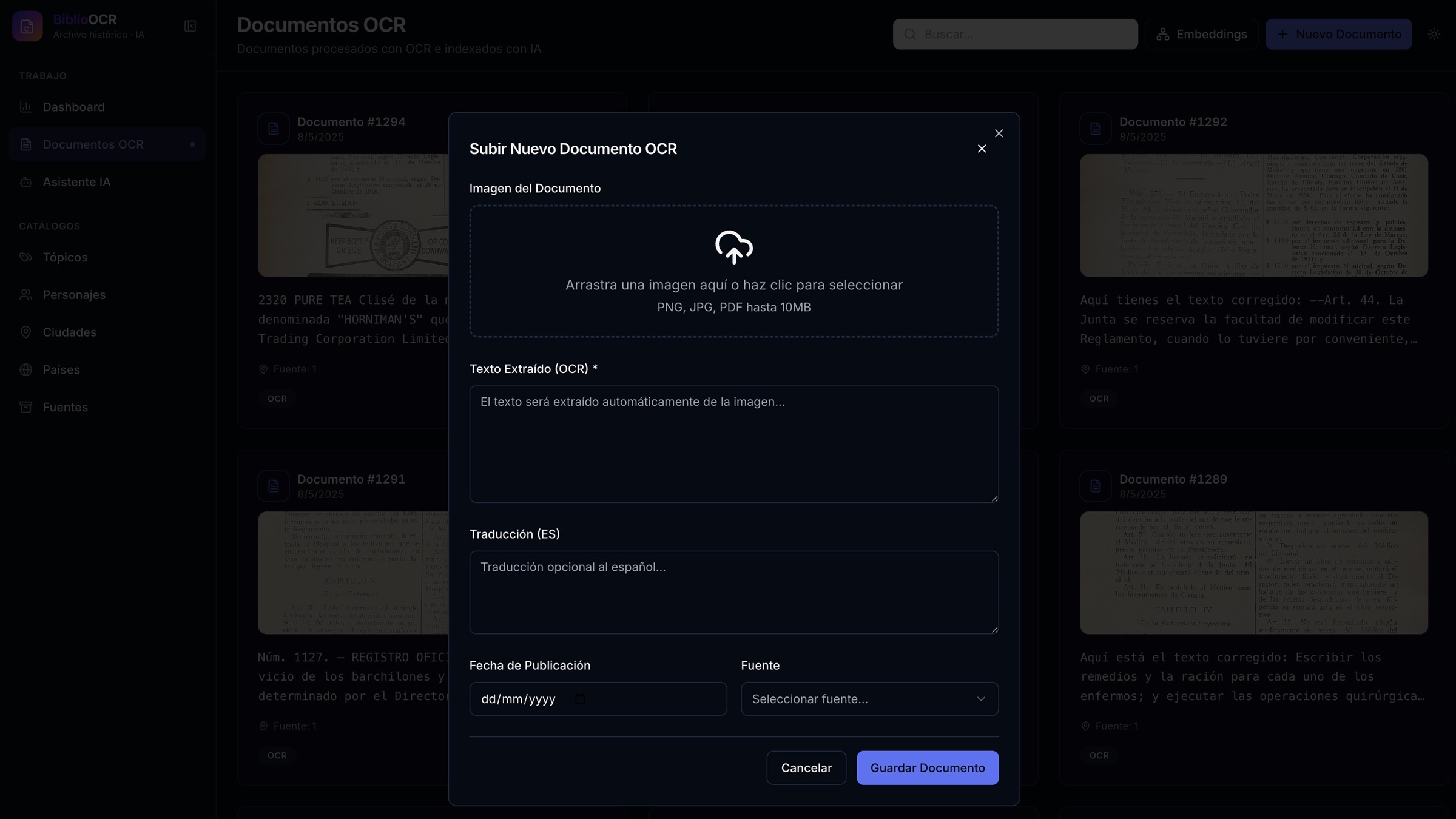
- Tres motores seleccionables por documento — Tesseract.js (local, offline), Google Cloud Vision (alta precisión) y Google Vision Columnar (optimizado para columnas tipográficas de periódicos y registros oficiales).
- Reproceso individual con preview antes de aplicar, para comparar resultados sin contaminar el texto persistido.
- Mejora de texto OCR asistida por LLM que corrige errores típicos de papel envejecido y tipografías del s. XIX, con revisión humana antes de guardar.
- Edición inline del texto OCR con re-cálculo automático de embeddings al guardar.
Búsqueda semántica sobre el corpus
- Embeddings vectoriales por chunks almacenados en PostgreSQL con pgvector — la búsqueda funciona por significado, no por palabra exacta.
- Búsqueda de documentos similares por proximidad en el espacio vectorial, clave en un corpus con ortografía variable y abreviaturas legales.
Asistente conversacional con RAG
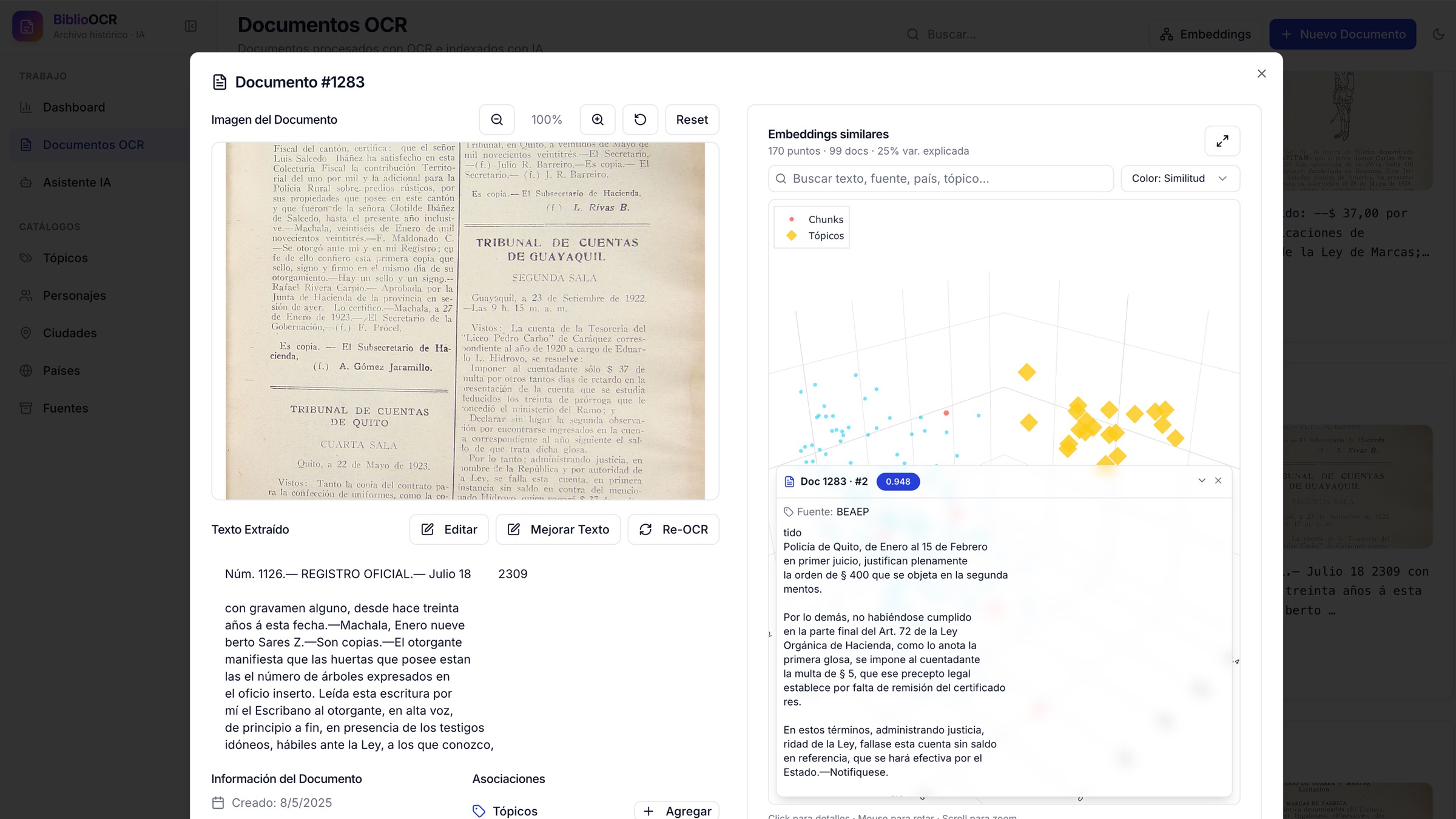
- Responde preguntas sobre el archivo citando documento + chunk como fuente, con vista lateral del documento referenciado.
- Trabaja sobre los mismos embeddings indexados, sin pipeline aparte.
Visualización 3D del corpus
- Vista global del corpus completo con PCA a 3 dimensiones (hasta 500 chunks), coloreado conmutable por tópico, fuente, país o cluster k-means, y búsqueda en vivo dentro de la nube.
- Documentos similares anclados al documento abierto: el plot se centra y resalta los chunks cercanos, con panel deslizable de detalle por punto.
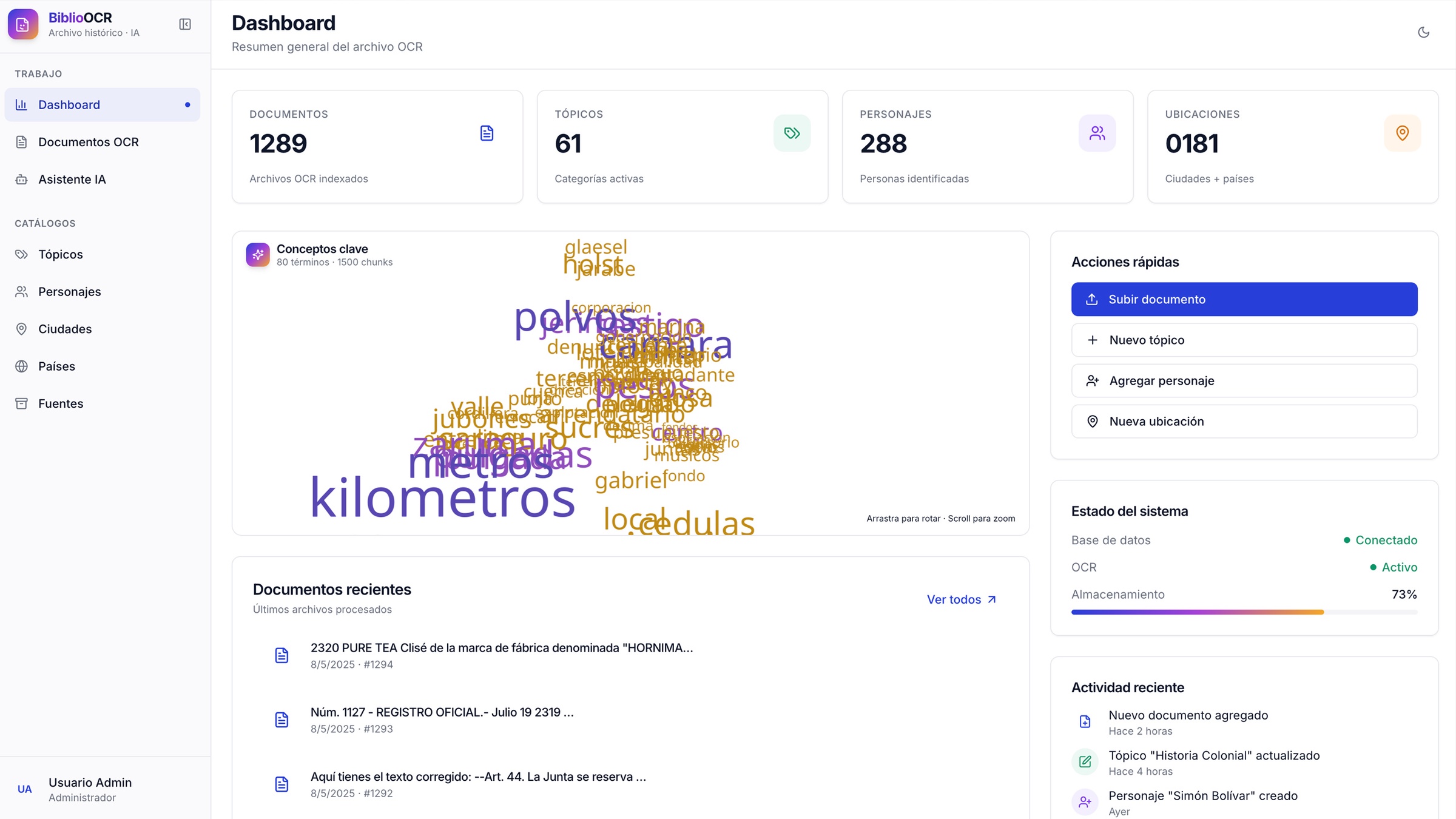
- Nube 3D de conceptos clave en el dashboard — extracción TF-IDF con ~180 stopwords en español + filtros de filler legal (art., decreto, ministerio, etc.); cada término se posiciona en el centroide PCA de los chunks donde aparece, render con React Three Fiber (auto-rotación, hover con outline, click navega a la búsqueda).
Catálogos y operación
- Catálogos manuales (tópicos, personajes, ciudades, países, fuentes) con asociaciones documento ↔ entidad y conteo automático.
- Traducción EN→ES preservada para documentos en inglés.
- Layout shell único con sidebar colapsable persistido, navegación agrupada (Trabajo / Catálogos), tema claro/oscuro con bootstrap pre-render para evitar flashes.
Resultados
- La búsqueda semántica reemplaza la búsqueda por palabra clave: el sistema encuentra documentos por concepto aunque no compartan vocabulario exacto — decisivo para corpus con ortografía variable del s. XIX y abreviaturas legales.
- Reducción del tiempo de revisión OCR gracias al flujo Tesseract → Google Vision → LLM con preview comparativo.
- La visualización 3D del corpus convierte una pregunta del tipo "¿qué hay aquí?" en una exploración visual del archivo entero, no en una lista de resultados.
Métricas concretas (documentos procesados, chunks indexados, embeddings vigentes, % de categorización automática correcta) — disponibles bajo NDA al avanzar la conversación.
Por qué importa
BiblioOCR demuestra que la IA aplicada a humanidades no termina en el OCR. El verdadero salto ocurre cuando los embeddings, el RAG y la visualización 3D se integran en un mismo producto, sobre datos reales del cliente, con la disciplina de ingeniería que exige una plataforma en operación. Es el mismo nivel de cuidado que llevamos a cada custom app que construimos.